June 22, 2026
I Built an AI Company That Tries to Open One Open-Source PR Every Day
A field report on building a small Paperclip company that discovers issues, opens focused open-source pull requests, and follows up on them.
For years, I wanted to contribute more to open source.
Not in the abstract, not as a line in a bio, but in the simple practical sense: find a project I use or respect, understand a small problem, submit a pull request, and leave the project a little better than I found it.
I had done that a few times, timidly. A small fix here, a documentation improvement there. But open-source contribution has always had a strange activation energy. You need to find the right issue, understand the repository, set up the environment, avoid stepping on existing work, write a respectful PR, respond to maintainers, and follow through.
At the same time, I had discovered Paperclip.
Paperclip was intriguing, but also slightly hard for me to place in my normal day-to-day work. Most of my daily work is made of specific, scoped tasks: fix this bug, inspect this system, write this document, change this configuration. For that kind of work, I already had a clear interaction model with tools like Codex.
Paperclip seemed to ask for something different.
It was not just another assistant. It was built around the idea of agents with roles, routines, memory, task handoffs, and company-like coordination. That sounded powerful, but I needed a scenario where this structure was not just interesting as a demo. I needed a use case where delegation, follow-up, and recurring work were actually part of the problem.
At some point, the obvious question became hard to ignore:
Could I build a small autonomous AI company whose job is to open one useful open-source pull request per day?
Not a coding assistant waiting for me to ask a question. Not a one-shot prompt that generates a patch. An actual workflow: discovery, implementation, review, pull request, maintainer follow-up.
That is where the two threads met.
I wanted to contribute to the open-source community, and I wanted to test Paperclip in a scenario that felt realistic enough to justify its company-like model.
So I built one.
I called it One PR a Day.
The Idea: Do a Little Good, Automatically
The original goal was intentionally small.
I did not want an agent that rewrites frameworks, performs heroic migrations, or attempts large architectural changes in repositories it barely understands. That sounds impressive, but it is also a good way to waste maintainers’ time.
Instead, I wanted something much narrower:
- find a small GitHub issue
- prefer active repositories
- avoid issues that already have an open PR
- make a focused change
- submit a pull request that is easy to review
- check back every day for CI, comments, and maintainer feedback
In other words: not “replace a developer”, but automate the kind of small, bounded contribution I would be comfortable reviewing myself.
That constraint matters. The point of this experiment is not to dump AI-generated work on maintainers. The point is to create a workflow where the agent does useful work, while I still remain accountable for the public contribution.
The Stack: Codex Builds the Company, Paperclip Runs It
The most interesting part of the experiment was not the first version of the setup. It was the moment Paperclip stopped being an abstract tool I was trying to understand and became the runtime for a concrete workflow.
At first, I tried to configure Paperclip by hand. Paperclip is easier to launch locally than to operate as a small persistent service on a remote server, so the initial deployment had some friction. More importantly, I was still treating it as a tool to configure, not as a system to design around.
Then I asked myself a meta-question:
What happens if I use Codex to set up Paperclip?
That changed the whole paradigm.
I was using an agent to build and operate a company of agents.
Codex became my direct assistant: the tool I used to inspect the server, configure the Docker deployment, tune the database, adjust the agent instructions, and refine the operating model.
Paperclip became the runtime for the company: the place where agents have roles, receive tasks, create child tasks, run on schedules, and persist operational memory.
The result is a small autonomous workshop.
There is an org chart. There are responsibilities. There are recurring routines. There is a task board. There is follow-up.
That is the part that made the experiment feel different from a normal “AI coding” workflow.
The Company Org Chart
The current One PR a Day company is deliberately small.
It has four agents in the system, but three of them carry the day-to-day contribution loop:
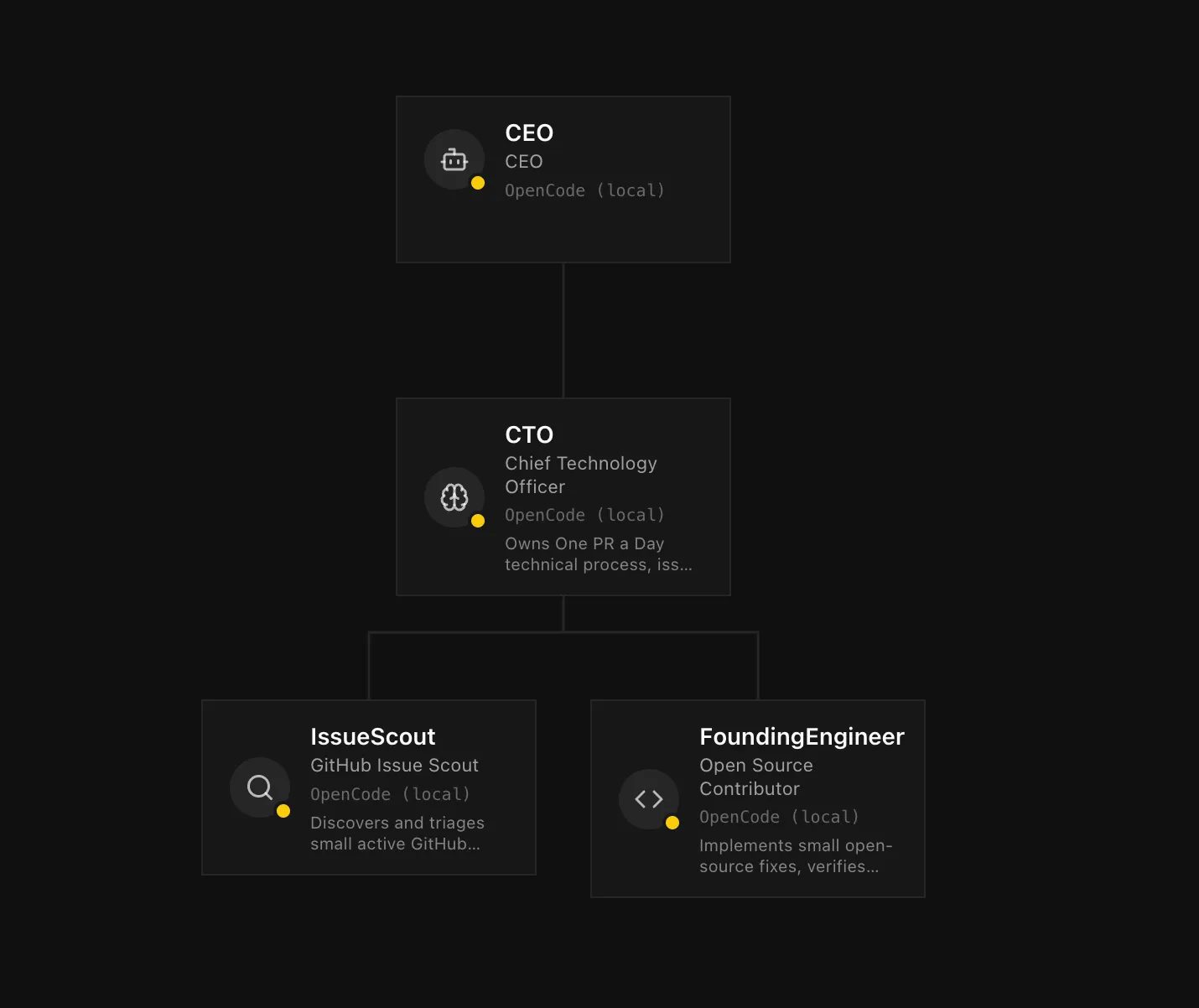
The One PR a Day organization inside Paperclip: governance at the top, process ownership in the middle, discovery and implementation at the bottom.
IssueScout
IssueScout owns discovery and triage.
Its job is to search GitHub, evaluate candidate issues, reject work that looks too large or risky, and create one implementation task only when a candidate passes the selection criteria.
At first, the search space was broad: any small open-source issue could be a candidate. Over time I narrowed the preference toward projects related to AI agents, developer automation, token/context optimization, model routing, observability, and adjacent tooling. That made the output more aligned with the rest of my experiments.
FoundingEngineer
FoundingEngineer owns implementation.
Once IssueScout creates a concrete implementation task, FoundingEngineer clones the repository, reads the issue, changes the code or docs, runs whatever verification is practical, opens the PR, and records evidence.
It uses a stronger model than the scouting role, because implementation is where reasoning mistakes become public mistakes.
CTO
CTO owns the process.
It reviews the workflow, follows up on open PRs, checks CI, watches for maintainer comments, and decides whether the company should continue, wait, escalate, or abandon a contribution.
This role turned out to matter more than I expected.
Opening a pull request is not the end of contribution. Sometimes it is the beginning.
There is also a CEO agent, but in this workflow it is mostly a governance and escalation role. The daily mechanics are handled by IssueScout, FoundingEngineer, and CTO.
The Workflow That Actually Worked
The first version of the workflow was too generic.
It was tempting to create a single task that meant “find something and fix it.” That is how humans often speak, but it is not a good structure for autonomous agents.
The useful redesign was organizational, not just technical.
Every contribution attempt now has two levels:
-
Discovery task
Find a candidate issueThis belongs to IssueScout. It is about finding and evaluating candidates.
-
Implementation task
Fix OWNER/REPO#ISSUE - short problemThis belongs to FoundingEngineer. It becomes the canonical thread for the PR lifecycle.
The implementation task is where the system tracks:
- repository and issue
- branch
- pull request URL
- CI status
- maintainer comments
- requested changes
- follow-up actions
- final outcome
This sounds like a small process detail, but it is one of the most important lessons from the experiment.
Autonomous agents need crisp ownership boundaries.
If discovery and implementation live in the same vague task, the workflow becomes muddy. The agent may mix candidate evaluation with coding, lose the PR URL, forget where maintainer feedback belongs, or treat a follow-up as a new unrelated problem.
Once I split discovery from implementation, the system became much easier to inspect and improve.
Daily Schedules Beat Continuous Autonomy
The system does not try to be constantly active.
That was a deliberate choice.
The current routine is closer to a daily operating rhythm:
- IssueScout runs daily discovery
- FoundingEngineer works on the selected implementation task
- CTO performs daily PR follow-up
This is enough.
In fact, “enough” is one of the most underrated words in agent design.
If the goal is one useful PR per day, you do not need a swarm of agents constantly burning tokens. You need one good candidate, one focused implementation, and one reliable follow-up loop.
At the time of writing, the internal Paperclip board for this company contains dozens of completed tasks, including daily discovery runs, follow-up runs, and implementation tasks. The public metric I care about most, though, is simpler: the GitHub pull requests themselves.
You can see the public trail on my GitHub profile. Two representative examples from the experiment are:
- Fmarzochi/EGC#395, a small fix around JSON decoding in an OpenRouter provider path.
- rtk-ai/rtk#2522, a contribution tied to the RTK project and its own contribution process.
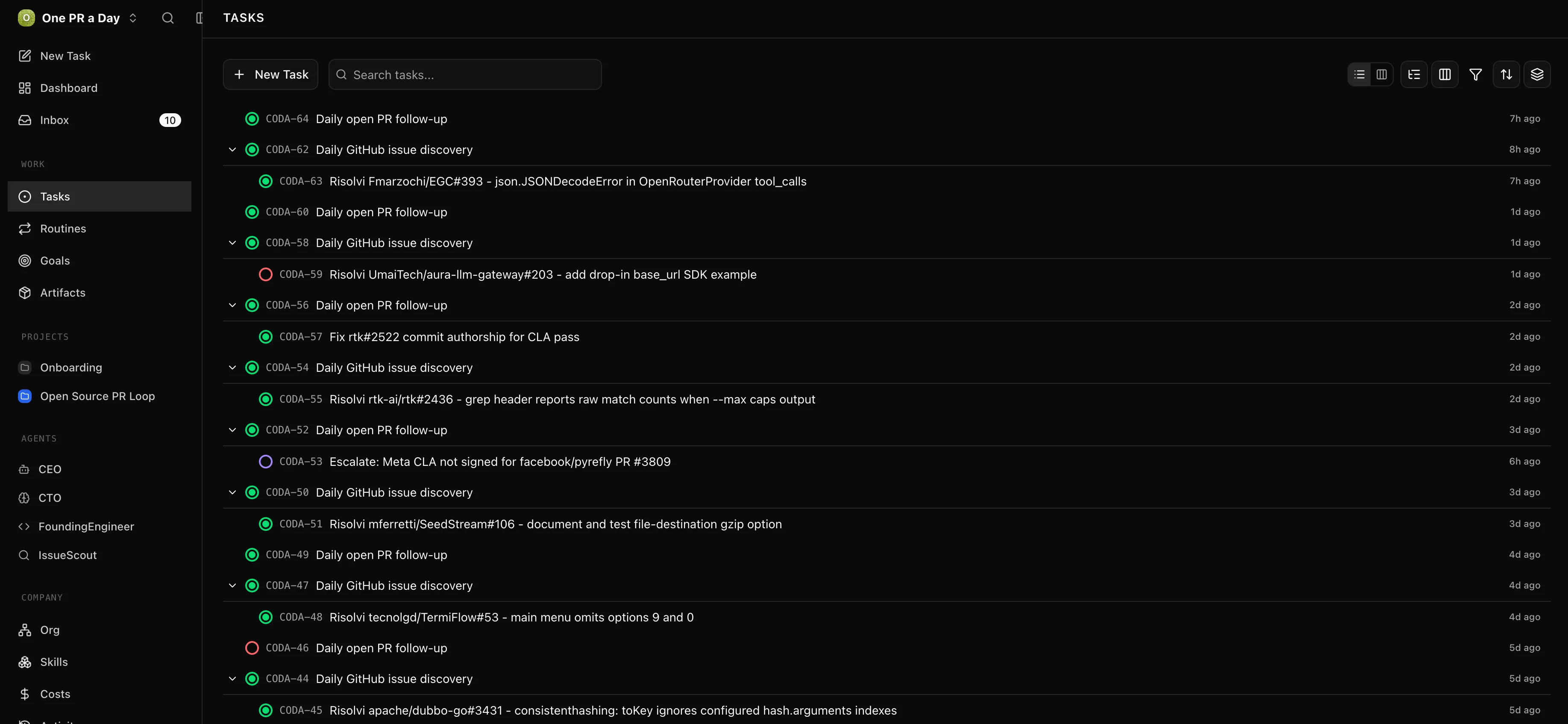
The task board makes the workflow inspectable: daily discovery creates implementation work, and follow-up tasks keep open PRs from being forgotten.
Model Routing and Cost Control
The first version was too expensive.
I initially used more capable, more expensive models for too much of the workflow. It worked, but the token burn was not sustainable. After a few days, it was clear that the system would not survive the monthly budget if every role behaved like a senior engineer reading the whole internet.
So I optimized.
The current setup routes different roles to different OpenCode Go models:
- cheaper/faster models for scouting and process follow-up
- stronger models for implementation
- daily cadence instead of noisy continuous activity
For the One PR a Day company itself, a recent seven-day sample from Paperclip recorded about $2.85 total, roughly $0.41/day. Across the broader Paperclip setup, the goal is to keep the whole experiment comfortably under $2/day, which makes it sustainable enough to keep running and learning from it.
That is another practical lesson: agent design is not only about capability. It is also about economics.
The question is not “what is the best model?”
The better question is:
What is the cheapest model that can reliably perform this specific role inside this specific workflow?
What the Agents Did Well
The surprising part is that the agents became quite good at the mechanical parts of open-source contribution.
They can usually:
- read a small issue
- understand the expected scope
- make a focused code or documentation change
- write a reasonable PR description
- interact with issue and PR comments
- adjust after maintainer feedback
- keep the contribution narrow
Most of the actual code changes have been good enough that my role is often just to give the PR a quick visual review.
That does not mean the system is magic. It means the workflow is narrow enough that the agents are operating in a tractable space.
Small issue. Small patch. Visible verification. Human accountability.
That combination works much better than asking an agent to “go improve open source.”
What the Agents Did Badly
The agents initially lost pieces of the contribution lifecycle.
Sometimes they would open a PR and not follow up properly. Sometimes the state was scattered across generic tasks. Sometimes the next action was obvious to a human but not represented clearly enough for the agent.
The most human-only blocker so far has been the CLA.
Some repositories require a Contributor License Agreement before a PR can be accepted. I did not even think about this as a workflow concern at the beginning, but it matters: an agent should not accept legal terms on my behalf.
That is still my job.
When a CLA is required, I read it and decide whether to approve it.
This is a useful boundary. There are parts of contribution that can be automated, and parts that should remain explicitly human.
The Ethics: Do Not Make Maintainers Pay for Your Automation
This experiment lives in a sensitive space.
Open-source maintainers already deal with noise: low-quality issues, drive-by PRs, automated spam, vague bug reports, and people who disappear after creating work for others.
Adding AI to that ecosystem can make things worse if we are careless.
My current rule is simple:
If I would be embarrassed to send the PR myself, the agent should not send it either.
That is why the scope is intentionally small. That is why I check the PRs. That is why the system prefers issues that are clear, bounded, and reviewable.
The agent is doing work under my name, and I am responsible for it.
I know some maintainers are skeptical of AI-generated contributions. Honestly, that is part of the reason I do not frame each PR as a public AI demo. I am not trying to make a point inside someone else’s issue tracker. I am trying to contribute a small fix.
The ethical bar should be outcome-based:
- Is the PR useful?
- Is it small?
- Is it easy to review?
- Does it respect the repository’s process?
- Does it respond to maintainer feedback?
- Is there a human accountable for it?
If the answer is no, the automation should stop.
What Makes a Good Candidate Issue
The best candidate issues are boring in the right way.
They usually have:
- small scope
- recent maintainer activity
- clear reproduction steps or expected behavior
- a code path that can be inspected quickly
- test or documentation surface that can be updated
- no existing PR already solving the problem
- low security, licensing, or governance risk
I also prefer repositories where the contribution process is visible and conventional: issues, PRs, CI, review comments, and clear maintainer expectations.
This is not because agents cannot handle complexity.
It is because maintainers should not have to absorb unnecessary complexity from my experiment.
The Most Interesting Lesson
Before doing this, I thought the hard question was:
Can an AI agent write code?
After running the experiment, I think that question is too narrow.
The more useful question is:
Can an AI agent choose the right work, do it in a bounded way, prove it, and follow through?
Code generation is only one part of contribution.
The harder parts are judgment, process, memory, and accountability.
That is why the company metaphor is useful. Not because agents are people, and not because we should pretend they are. It is useful because work needs structure:
- who finds opportunities?
- who decides if they are worth doing?
- who implements?
- who follows up?
- where is state recorded?
- when should a human intervene?
Once those questions are explicit, the agents become more useful.
What I Would Change If I Started Again
The main infrastructure change I would make is the database.
Right now the deployment uses the embedded database inside the Docker-based Paperclip setup. It works, but if I started again I would probably use an external PostgreSQL instance from day one.
For an experiment, the embedded setup was fine.
For something I expect to keep running, inspect, back up, and migrate over time, external Postgres would be cleaner.
I may still migrate it in the future.
Where This Is Going Next
The experiment is already useful enough that I want to keep it running.
The next improvements are not glamorous. They are mostly operational:
- better public metrics on PRs opened and merged
- better weekly reporting
- clearer tracking from candidate issue to final PR outcome
- more explicit cost-per-useful-contribution reporting
- more robust backup and migration strategy
- stricter candidate scoring before implementation starts
That is the shape of real agent work, at least for me.
Not a spectacular demo.
A small system, doing a small useful thing, repeatedly.
Conclusion: Agents Need Workflows, Not Wishes
“One PR a day” sounds like a simple prompt.
It is not.
It is an operating model.
The most valuable part of the experiment was not discovering that an AI agent can edit code. We already knew that. The valuable part was learning how much structure is required around the code:
- narrow goals
- explicit roles
- scheduled routines
- task ownership
- PR follow-up
- human review
- cost control
- ethical constraints
That is where AI agents start becoming useful in practice.
Not when they are asked to do everything.
When they are given a small job, a clear process, and enough accountability to do it without making the world worse.
For me, that job is currently simple:
Open one small, respectful, useful pull request per day.
And then come back tomorrow to see what happened.